About Me
I am a tenured associate professor of management science at the Argyros College of Business & Economics at Chapman University. While I am a theoretical physicist by training,
I apply mathematical and computational tools from statistical physics to large-scale
empirical and data-oriented research in computational social science, business and
economics. After my Ph.D. and prior to joining the faculty at Chapman, I worked as an assistant professor at
Questrom School of Business at Boston University, where I mentored two incredible Ph.D. students, Kai Zhu and
Chen Chen, and an awesome postdoctoral research associate,
Hyunuk Kim. Prior to that, I worked as a postdoctoral research associate at
NYU Stern with
some wonderful people, including Sinan Aral,
Lev Muchnik, and Sean Taylor.
If you'd like to know more, have a peek at my CV, check my selected published papers
below or see my google scholar page for a complete list of publications. You can also find
me at rare times on twitter @dylanwalker.
My Research
How are things connected? How do ideas, behaviors, and products spread? How do individual dynamics (interactions between people) lead to macroscopic outcomes (memes, trends, and social movements)? On modern platforms, digital traces of human behavior for tens of millions of people are the new microscope, enabling research into human behaviors and social and economic outcomes at an unprecedented scale and level of detail, orders of magnitude greater than what was possible before.
But our platforms don't just enable us to measure, they also facilitate new patterns of human behavior (sometimes for the good, sometimes for the bad). My research aims to develop an empirical (i.e., data-based) understanding of the dynamics of human interaction in modern platforms and how these dynamics lead to contagions (macro outcomes). I also want to understand how feature and policy choices of platforms shape the information that flows through them. Are our social platforms distorting information? How and why and what might we do to change that?
A big part of answering these questions is getting the right (often large-scale) data and figuring out how to analyze it. Causal insights are best, but are tough because the connectedness of networks makes it challenging to design clean experiments on them. Deriving causal insights from observational data in networks is notoriously challenging because there are a lot of confounds. Finding "natural experiments" can help.
Some specific topics that I am interested in are:
- Design and Analysis of Randomized Experiments in Networks
- Social Influence and Peer Effects in Online Social Networks
- Gun Violence and Media Coverage
- The Impact of Ownership on Local Televised News
- Misinformation in Social Media
- The Interactions of Social Media and Television
- The value of higher education
How are influential people and susceptible people distributed across social networks?
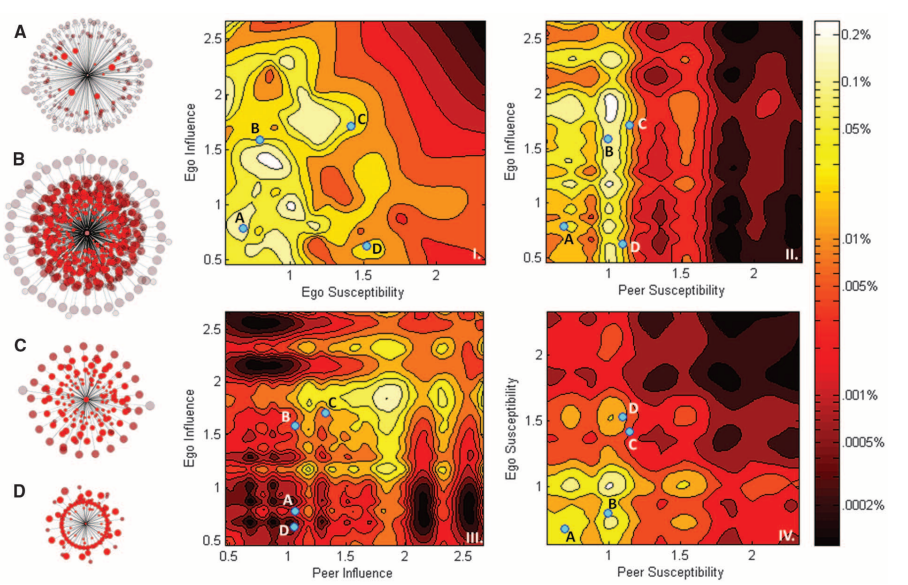
Experiments in online social networks can help us causally estimate scores of how much people influence their peersand how susceptible they are to influence from their peers. How are these people distributed on networks? Are influential people also susceptible? Nope. Are people influential because they have gullible peers? Not really -- the two are independent. Do influential people tend to have influential peers? Yep. Do gullible people cluster in the network? Nope. The answers to these questions help us understand how contagions -- large connected individuals "doing the same thing together" -- come about.
How does new information causally drive consumption of knowledge?
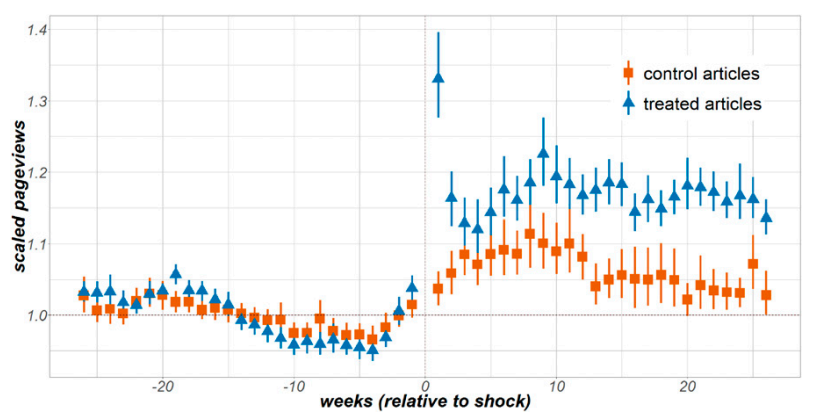
Using a natural experiment driven by the Wiki Education program (where people add content to Wikipedia as part of college courses), we learn that: When people edit Wikipedia pages and add content, it causes others to view the pages more. That extra attention also spills over onto yet other pages, and even more so across newly created links. This attention also causes editors to focus more on developing pages. This discovery can be turned into a policy to help magnify spillover effects, driving attention to the places in Wikipedia that need it the most!
How might forces of attraction and repulsion within and between groups pull us together or drive us apart?
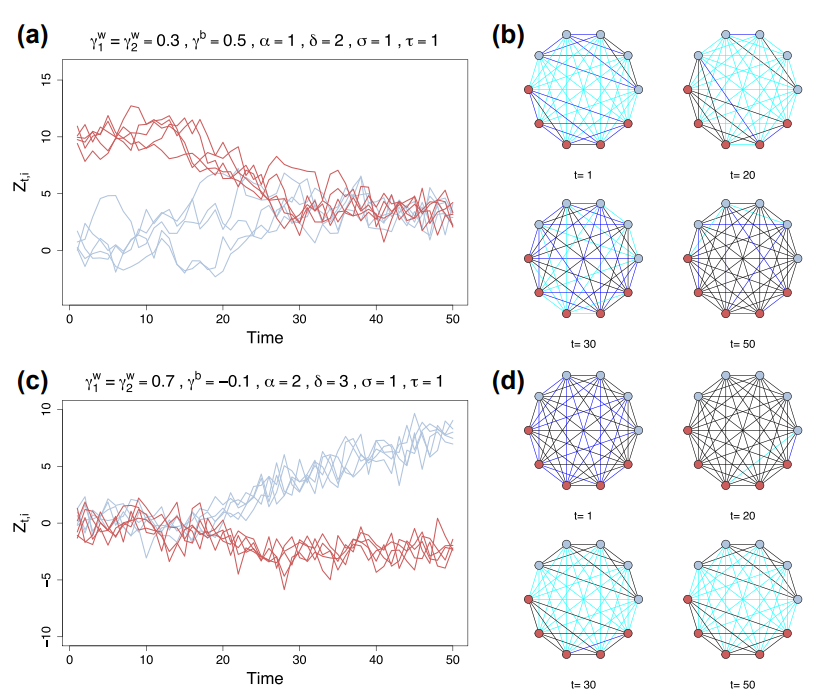
To study how the forces within and between groups (of people, e.g., democrats/republicans) lead to different patterns of people connecting, we construct a new class of statistical models called "Co-evolving Latent Space Network models with Attractors" or CLSNA. Its a mouthful, but the idea is simple. Every person is situated in a 2D space that we don't see and their position in that space evolves. Their connections with others (the network) also evolves, so its a co-evolving model. We introduce some attractors into the space that can pull/push people toward/away. By using different attractors for people in the same and different groups, we can explore how different regimes of the model lead to either flocking (groups pulling together and connecting) or polarizing (groups pushing apart and disconnecting).
How good is online medical advice? How good are patients at evaluating it?
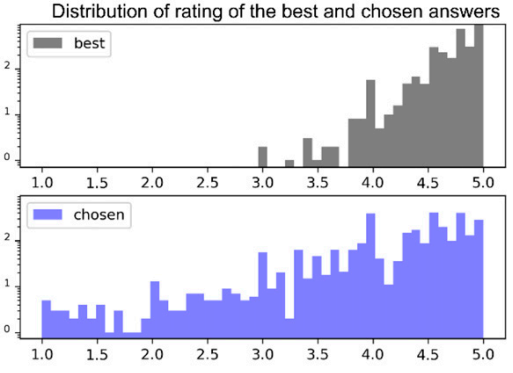
Patients getting medical advice from physicians online is all the rage, especially in China. We gather this data to learn how good the advice is. On average, it's pretty good! But we also learn that patients can't tell the good advice from the bad. We build neural network models and train them to think like patients. This allows us to learn how patients choose advice. Their biases play a big role. They don't like to hear bad news and don't like being told to get follow-up care. We also learn that platforms like the one we studied have some bad actors on them (pushing drugs or spamming answers). The platforms need to ensure that physicians evaluate the advice given by other physicians. If they don't, the best doctors don't earn the highest reputation on the platform.
How does AI-assisted machine translation help increase knowledge and close knowledge gaps?
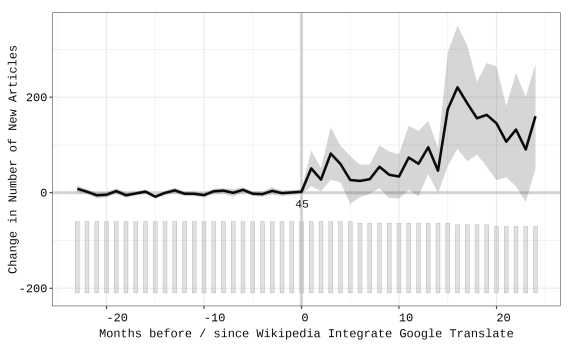
Language barriers prevent people from accessing knowledge on online knowledge platforms like Wikipedia. Can advances in machine translation (MT) (that leverage machine learning and AI) help make knowledge more accessible? We look before and after the time that Wikipedia introduced Google Translate (a sophisticated machine translation tool) and find that it has a huge impact on pages produced in new languages. The effect isn't equal across all categories, culture and geography related pages get created more (via editor-assisted MT) . Interestingly, editors seem to use MT to narrow some systemic gaps in knowledge across gender and geography relative to pages produced by means other than machine translation.
Listen to my research
If you'd rather listen, here are some AI-generated podcasts about my research (don't worry, they're pretty decent):
Selected Publications
Is Peer Influence Essential for Success?
N Livneh, D Walker, L Muchnik, J Goldenberg
Working Paper
Stochastic gradient descent-based inference for dynamic network models with attractors.
H Pan, X Zhu, C Caliskan, DP Christenson, K Spiliopoulos, D Walker, ED Kolaczyk
Under review
The Promise and Pitfalls of AI Technology in Bridging Digital Language Divide: Insights from Machine Translation on Wikipedia.
K Zhu & D Walker
Under review
Disentangling positive and negative partisanship in social media interactions using a coevolving latent space network with attractors model
X Zhu, C Caliskan, DP Christenson, K Spiliopoulos, D Walker, ED Kolaczyk
Journal of the Royal Statistical Society Series A: Statistics in Society, 186(3), 463-480 (2023)
Ideology Prediction from Scarce and Biased Supervision: Learn to Disregard the “What” and Focus on the “How”!
C Chen, D Walker, and V Saligrama
Proc. 61st Assoc Computational Linguistics (1),9529–9549 (2023)
Understanding the Consumption of Antimicrobial Resistance–Related Content on Social Media: Twitter Analysis
H Kim, CR Proctor, D Walker, RR McCarthy
Journal of Medical Internet Research 25, e42363 (2023)
A Bitter Pill to Swallow: The Impact of Patient Evaluation on Online Health Q&A Platforms
C Chen and D Walker
Information Systems Research 34 (3), 867-889 (2023)
If a Tree Falls in the Forest: COVID-19, Media Choices, and Presidential Agenda Setting
M Krupenkin, K Zhu, D Walker, & DM Rothschild
Journal of Quantitative Description: Digital Media, 2 (2020)
Leveraging volunteer fact checking to identify misinformation about COVID-19 in social media
H Kim & D Walker
Harvard Kennedy School Misinformation Review, 1(3) (2020)
Content Growth and Attention Contagion in Information Networks: Addressing Information Poverty on Wikipedia
K Zhu, D Walker, & L Muchnik
Information Systems Research 31 (2), 491-509 (2020)
Understanding and diagnosing antimicrobial resistance on social media: a yearlong overview of data and analytics
B Andersen, L Hair, J Groshek, A Krishna, & D Walker
Health communication, 34(2), 248-258 (2019)
Design of Randomized Experiments in Networks
D Walker and L Muchnik
Proceedings of IEEE, 04 Nov 2014 102(12) pp. 1940-1951 (2014)
Tie Strength, Embeddedness & Social Influence: A Large-Scale Networked Experiment
S Aral & D Walker
Management Science, 21 April 2014, 60(6) pp. 1352-1370 (2014)
An Experimental Method for Identifying Influential and Susceptible Members of Online Social Networks
S Aral & D Walker
Science, Vol. 337 no. 6092 pp. 337-341 (2012)
Creating Social Contagion through Viral Product Design: A Randomized Trial of Peer Influence in Networks
S Aral & D Walker
Management Science 57 (9), 1623-1639 (2011)
*Selected as an Editor’s Choice article by the editors of Science
Identifying Social Influence in Networks Using Randomized Experiments
S Aral & D Walker
IEEE Intelligent Systems 26 (5) (2011)
Forget Viral Marketing: Make the Product Itself Viral
S Aral & D Walker
Harvard Business Review, 89 (6) (2011)
Fluctuations in Mass-Action Equilibrium of Protein Binding Networks
KK Yan, D Walker, S Maslov
Physical Review Letters, 101 (268102) (2008)
Ranking Scientific Publications Using a Model of Network Traffic
DWalker, H Xie, KK Yan, S Maslov
Journal of Statistical Mechanics, 6 (10) (2007)
Patents
Patent 20140310058: Identifying Influential and Susceptible Members of Social Networks
Provisional Patent 62/372,480: Method of identifying repetitive patterns in big data and system thereof